transformers is a well-known python package that wraps various model’s implementation. It provides an easy way to implement/modify/create various models.
A usual implementation for causal llm look like below:
1 2 3 4 5 6 7
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.1-8B-Instruct") model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.1-8B-Instruct")
outputs would contain a tensor for tokenizer to decode.
This article is to have an insight into how this model.generate works. To understand it, we need to look into the source code of transformers. We use transformers==4.44, and as transformers is being developed so actively, some of the code here may be outdated.
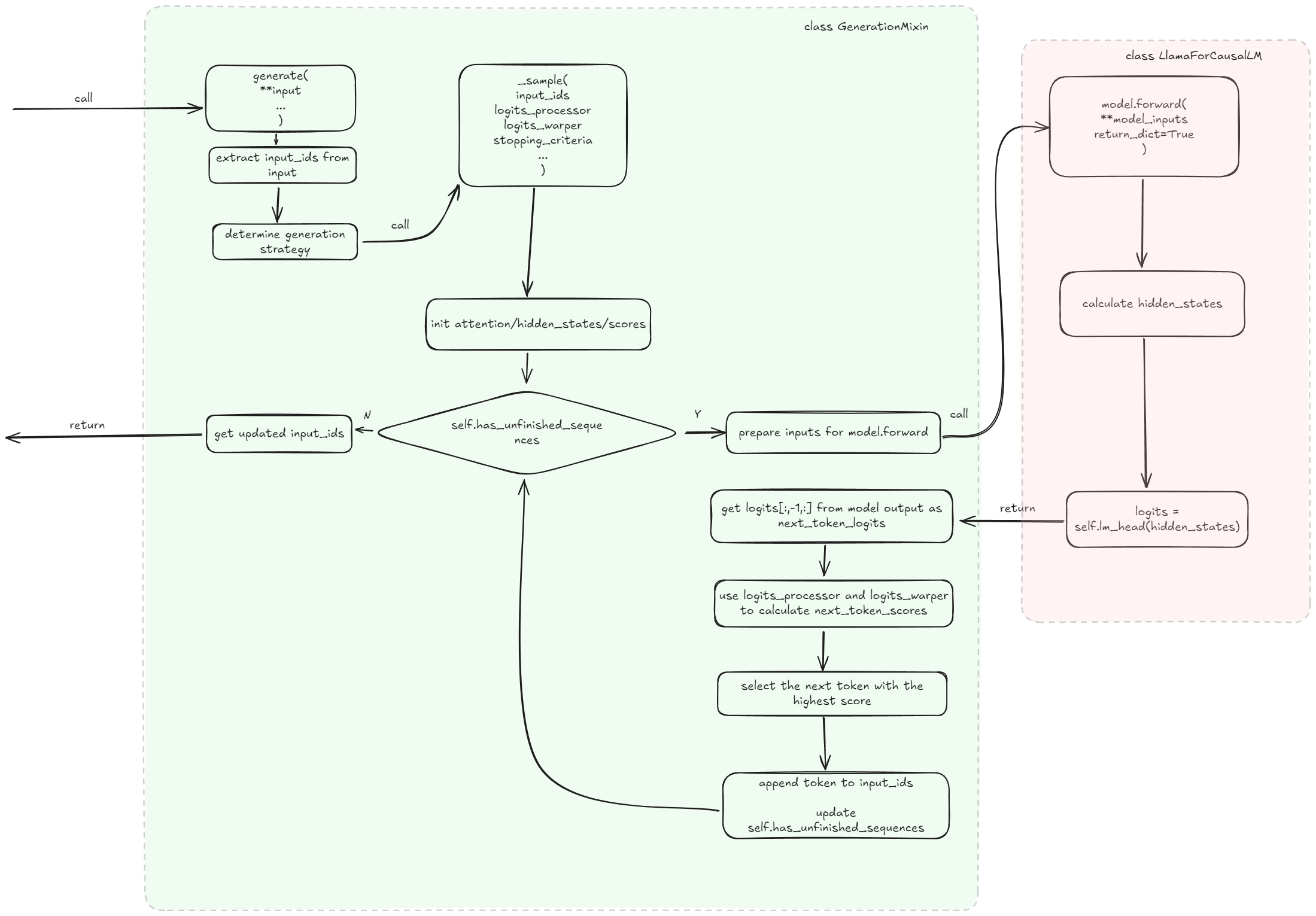
We focus on how the class GenerationMixin use the forward function in this article (How this ‘forward’ function work in LlamaForCausalLM is another topic). In this topic, we only need to know that LlamaForCausalLM.forward takes in some input_ids and other bunches of parameters, and return something called logits to its caller.
Here’s an overview when you call the function model.generate
Let’s begin with understanding this input argument in this generate function. Input is an object of a class called BatchEncoding, and it contains bunches of tensors like input_ids, attention_mask, etc. But that would be too much to discuss here. Anyway, generate extract data from this input with a member function called GenertionMixin._prepare_model_inputs
1 2 3 4 5 6
# 3. Define model inputs inputs_tensor, model_input_name, model_kwargs = self._prepare_model_inputs(
input_ids = inputs_tensor if model_input_name == "input_ids"else model_kwargs.pop("input_ids")
Then the code did some work about caching and generation constraints.
After that, the code need to determine the generation_mode of the model, create prepared_logits_processor and prepared_stopping_criteria for future use.
if streamer isnotNoneand (generation_config.num_beams > 1): raise ValueError( "`streamer` cannot be used with beam search (yet!). Make sure that `num_beams` is set to 1." )
ifnot is_torchdynamo_compiling() and self.device.type != input_ids.device.type: warnings.warn( "You are calling .generate() with the `input_ids` being on a device type different" f" than your model's device. `input_ids` is on {input_ids.device.type}, whereas the model" f" is on {self.device.type}. You may experience unexpected behaviors or slower generation." " Please make sure that you have put `input_ids` to the" f" correct device by calling for example input_ids = input_ids.to('{self.device.type}') before" " running `.generate()`.", UserWarning, )
Now, based on the generation_mode we extracted from generation config before, we can go into different generation mode.
1 2 3 4
# 10. go into different generation modes if generation_mode == GenerationMode.ASSISTED_GENERATION:... elif generation_mode == GenerationMode.DOLA_GENERATION:... ...
Basically it a bunch of if…elif… codes that leads to different generation implementation. For llama, the generation mode is called greedy_search, so we’ll just focus on that part of code.
In this branch of generate. prepared_logits_warper is created, and input_ids is expanded.
# 12. expand input_ids with `num_return_sequences` additional sequences per batch input_ids, model_kwargs = self._expand_inputs_for_generation( input_ids=input_ids, expand_size=generation_config.num_return_sequences, is_encoder_decoder=self.config.is_encoder_decoder, **model_kwargs, )
Then a critical function named _sample is called, it will call model.forward for many times and complete the main part of sequence generation.
1 2 3 4 5 6 7 8 9 10 11
# 13. run sample (it degenerates to greedy search when `generation_config.do_sample=False`) result = self._sample( #NOTE: model.forward wrapped in here input_ids, logits_processor=prepared_logits_processor, logits_warper=prepared_logits_warper, stopping_criteria=prepared_stopping_criteria, generation_config=generation_config, synced_gpus=synced_gpus, streamer=streamer, **model_kwargs, )
Its parameters are well documented in source code.
""" Generates sequences of token ids for models with a language modeling head using **multinomial sampling** and can be used for text-decoder, text-to-text, speech-to-text, and vision-to-text models. Parameters: input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`): The sequence used as a prompt for the generation. logits_processor (`LogitsProcessorList`): An instance of [`LogitsProcessorList`]. List of instances of class derived from [`LogitsProcessor`] used to modify the prediction scores of the language modeling head applied at each generation step. stopping_criteria (`StoppingCriteriaList`): An instance of [`StoppingCriteriaList`]. List of instances of class derived from [`StoppingCriteria`] used to tell if the generation loop should stop. generation_config ([`~generation.GenerationConfig`]): The generation configuration to be used as parametrization of the decoding method. synced_gpus (`bool`): Whether to continue running the while loop until max_length (needed for ZeRO stage 3) streamer (`BaseStreamer`, *optional*): Streamer object that will be used to stream the generated sequences. Generated tokens are passed through `streamer.put(token_ids)` and the streamer is responsible for any further processing. logits_warper (`LogitsProcessorList`, *optional*): An instance of [`LogitsProcessorList`]. List of instances of class derived from [`LogitsWarper`] used to warp the prediction score distribution of the language modeling head applied before multinomial sampling at each generation step. Only required with sampling strategies (i.e. `do_sample` is set in `generation_config`) model_kwargs: Additional model specific kwargs will be forwarded to the `forward` function of the model. If model is an encoder-decoder model the kwargs should include `encoder_outputs`. Return: [`~generation.GenerateDecoderOnlyOutput`], [`~generation.GenerateEncoderDecoderOutput`] or `torch.LongTensor`: A `torch.LongTensor` containing the generated tokens (default behaviour) or a [`~generation.GenerateDecoderOnlyOutput`] if `model.config.is_encoder_decoder=False` and `return_dict_in_generate=True` or a [`~generation.GenerateEncoderDecoderOutput`] if `model.config.is_encoder_decoder=True`. """
So what does it do?
First, it initializes bunches of values that are essential for generation, including setting up stopping_criteria, initialize attention, hidden_states and scores, doing extra work if we use encoder-dedcoder model.
Then a generation loop begins, its termination judged by a function called self._has_unfinished_sequences
1 2 3 4 5
while self._has_unfinished_sequences( this_peer_finished, synced_gpus, device=input_ids.device, cur_len=cur_len, max_length=max_length
): ...
Inside the generation loop, model_inputs are first prepared, and then passed to model’s forward function
Still remember the prepared_logits_processor and prepared_logits_wrapper? They are used here:
1 2 3 4
# pre-process distribution next_token_scores = logits_processor(input_ids, next_token_logits) if do_sample: next_token_scores = logits_warper(input_ids, next_token_scores)
How does it work? I don’t have time to see that yet, but we know that after this process, we get a score for each token(not just bare probabilities as logits is), then we can do the token selecton
Token with the highest score would be appended to input_ids. This piece of code also tells what to do when generation is complete
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
# finished sentences should have their next token be a padding token if has_eos_stopping_criteria: next_tokens = next_tokens * unfinished_sequences + pad_token_id * (1 - unfinished_sequences) # update generated ids, model inputs, and length for next step input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1) if streamer isnotNone: streamer.put(next_tokens.cpu()) model_kwargs = self._update_model_kwargs_for_generation( outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder, )
Then whatever it returns(Dictionary or Tensor) would just be returned to the caller of the generate function, so a call is completed.
Actually, some tasks are still done before final return, like tackling a compatibility issue about the past_key_values, which is a Tensor(legacy) or an object of class DynamicCache(current). But it doesn’t involve changing input_ids(at least for now)
Then we can convert this result to natural language using tokenizer.decode, which is very straightforward.
I’m really a rookie in Artificial Intelligence. Chewing transformers’ source code is quite a challenge for me, but also a lot of fun. If anything above disagrees with what the code actually does, I would appreciate corrections from comment below. Further questions are also welcomed.